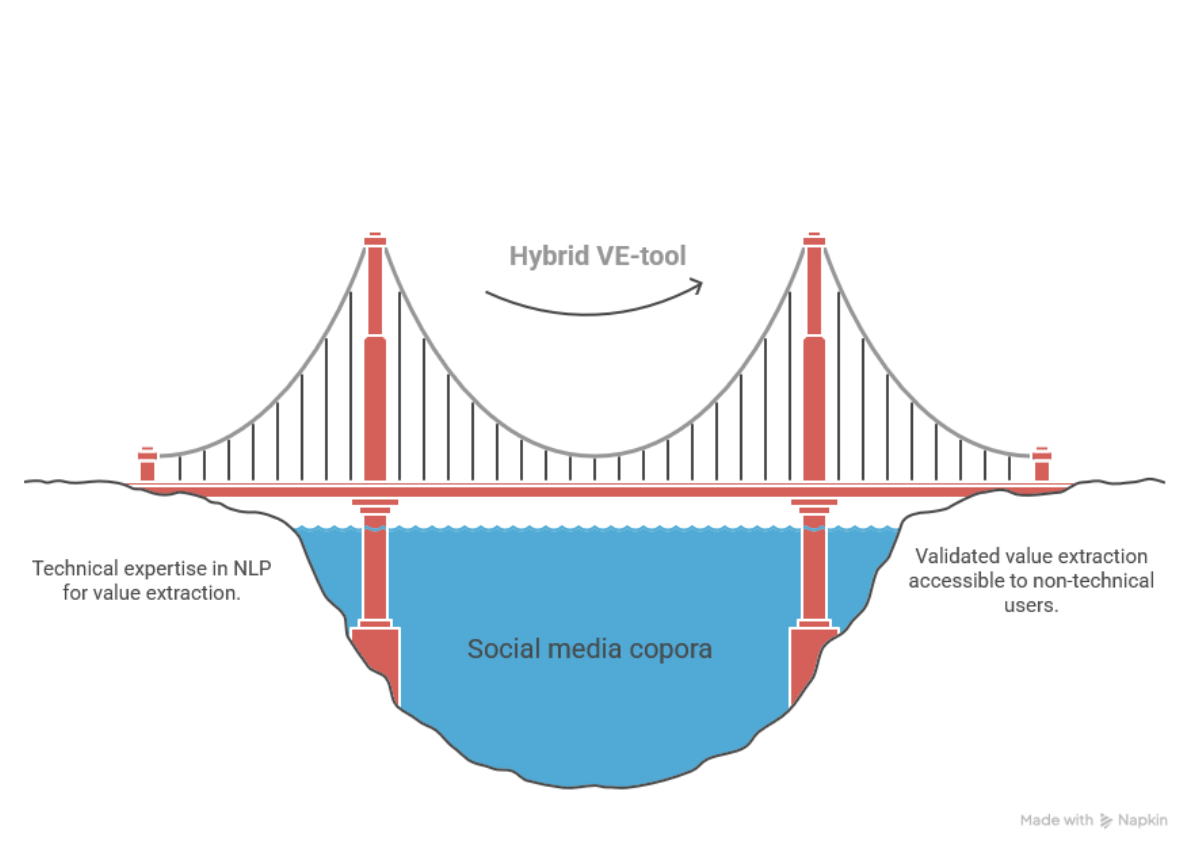
Social media contain a wealth of user-generated data concerning values and norms. Conventional value identification and extraction processes require significant technical expertise, confining their use in education and interdisciplinary research. This project will develop a hybrid Natural Language Processing tool to extract values from social media-sourced textual corpora, combining domain-specific embedding-based model training with user-friendly LLM (Large Language Model)-based prompt engineering. We aim for both validated extraction of heritage values in urban contexts and scalable application to new domains such as health and nutrition. The datasets and the tool will be used in research and education activities and published open source.
Developing a Hybrid Tool for Value Extraction from Social Media Sourced Textual Corpora

Nan Bai
Heritage; Climate Governance, Graph-Structured Data, AI, Social Media

Yan Zhou

Lavinia Marin
Social media, interaction design, human computer interaction, values in ICT, online values, online experiences, social norms online
Related Seed Projects
 Oct 24
Oct 24
SIG on Designing Technology for Mental Wellbeing
Our SIG focuses on designing technologies that support mental health and well-being. Common mental health disorders like depression and anxiety are leading causes of…
 Oct 24
Oct 24
SIG: Ethics and Design of Good Influence
A Special Interest Group focused on the ethics and design of good influence, exploring how design can positively influence behavior and society.
 Oct 24
Oct 24
SIG Education
Education SIG The Education SIG aims to bring together educators from across the TU Delft to strengthen the integration of values, such…